Why Local Knowledge Matters More Than Random Sampling in Community Science
We often hear that the best way to study something is to take a “random sample.” Random sampling is a technique where every sample has an equal chance of selection: any patch of water has the same chance of being selected to study a bay, any student at a university has an equal chance of being surveyed about their school. But in community-based environmental research, this method is rarely used. There are very good reasons for this, and it has to do with the knowledge bases that guide community science versus the type of research that needs random sampling.
Instead, community researchers rely on something different: local knowledge. When researchers are familiar with the place they’re studying, they often know exactly where to look, when to go, and what to focus on. This type of targeted selection is called purposive sampling, and while it’s often viewed with skepticism in traditional science, it yields better and more meaningful results in many community settings.
The problem is that purposive sampling is often viewed as less valid or even referred to as “biased.” That reputation has hurt the standing of community-based science. It’s time to rethink that.
This article explains why purposive sampling is not only valid but often better for environmental research done with and by communities. I’ll walk through the basics of sampling and representativeness, a brief history of how random sampling came to dominate, and how purposive sampling—guided by local knowledge—makes science more accurate and meaningful. Finally, I’ll offer some practical principles for doing purposive sampling well.
What is sampling?
Sampling is about selection. It’s about using a part (or several parts) to understand the whole.
If you want to know what a species of bird looks like, a few museum specimens might be enough—as long as you pick examples that represent the species well, such as both males and females, adults and fledglings. If you ask ten students whether they understand a lecture, it only tells you something useful if they’re not all sitting the front row.
Good sampling depends on good selection: choosing the right parts to stand in for the whole.
Representativeness
As you can see in these examples, how well a sample generalizes is an issue for the quality of the study, and the sampling design plays a central role. A sample is only useful if it represents what you’re trying to study so you can apply the findings more broadly.
But the word “representative” gets used in fuzzy ways. In their history of statistical sampling, Chasalow & Levy (2021: 83) point out, it often mixes different ideas: being typical, random, proportionate, or meaningful. It has both scientific and political weight—and can be used to include or exclude certain kinds of knowledge.
Put another way, as Chris Anderson has written in Indigenous Statistics, “different groups hold different amounts of power. Therefore, they can disproportionately affect what the statistics eventually come to look like” (2025: 33) including what counts as “truly” representative statistical methods.
The real question is: what is your sample supposed to represent, and for whom? In community-based science, that question becomes especially important.
A short history of sampling
Early science often looked for the “typical” example to represent a whole category. Natural history museums collected one or two birds of each species as stand-ins for the whole group. This was particularly the case when colonialism was extracting new-to-Europeans animals, plants, and People from the environment and scientific knowledge sought an archetype or average type to tell a “holistic truth” (Chasalow & Levy 2021: 78).

But by the 19th and early 20th centuries, governments in Europe and the United States wanted data that captured variation across populations they governed. They wanted census-style data that could see how groups within a population differed from one another. Questions about lying and misreporting became an issue.
That led to the rise of random sampling as a more “objective” method. Statisticians like Kiaer (1895) and Neyman (1935) helped formalize this approach, treating random sampling as a machine-like activity that was rule-based, emotionless, and unbiased. Random sampling is designed so any member of a population has the same chance of being selected, thereby creating an “approximate miniature” of the population in all of its variation (Kiaer 1895). This equal chance of selection was seen as the hallmark of unbiased, mechanical approaches (Chasalow & Levy 2021: 79).
Over time, random sampling became the default, so much so that it’s often confused with sampling itself. It’s what textbooks teach, what AI chatbots recommend, and what many scientists still assume is the “best” approach.
But there’s a cost: methods that rely on human insight, judgment, and relationships—like purposive sampling—have been pushed aside, even when they’re better suited to the research at hand.
The Problem with a Narrow Definition of “Good Sampling”
Most science textbooks do mention other types of sampling beyond random—but often with warnings. You’ll hear about convenience sampling (grabbing what’s easiest), snowball sampling (participants refer others), haphazard sampling (no system at all), opportunistic sampling (using samples from another study) and judgmental or purposive sampling (choosing based on knowledge). But these are usually framed as second-rate: less rigorous, more biased, and mostly for exploratory or qualitative work.
This framing creates a divide: random = good, everything else = risky.
That puts community science, including Indigenous science, which often relies on local, relational, or cultural knowledge, at a disadvantage. These knowledge systems are seen as “biased” rather than insightful, even when they produce more accurate or relevant results for the questions being asked.
What Is Purposive Sampling?
Purposive sampling means selecting what to study based on what you already know. It’s guided by relationships, experience, and local context. Not by chance.
One classic example: If you want to know the average length of people’s right arms, but only have data on their left arms, you could choose people with average-length left arms and then measure their right ones. Since left and right arms are strongly related, this would give you a solid estimate.
This works because you’re using a known relationship between two things (correlation) to guide your selection. And that’s the essence of purposive sampling: using knowledge you already have to make smart decisions about what to measure next.
That kind of judgment isn’t bias. It’s expertise. And in community-based research, that expertise often lives with the people who know the land, water, and community best. They have insights into what makes sampling properly representational.

Purposive sampling isn’t one-size-fits-all. Here are some common types (based on Rai, N., & Thapa, B. (2015)):
- Maximum variation sampling: Choose a wide range of cases to see what holds across diversity.
- Homogeneous sampling: Focus on a group that shares key traits to study those traits more closely.
- Typical case sampling: Study a “normal” example to see what a standard case looks like.
- Extreme case sampling: Focus on rare or unusual cases to understand big impacts or outliers.
- Critical case sampling: Study a particularly telling case to see if findings apply more broadly.
- Theoretical sampling: Let your early results guide where and what you sample next.
- Quota sampling: Choose a set number of cases that meet specific criteria.
These strategies let researchers match their sampling to their research goals—especially when questions are local, contextual, or specific.
Representativeness in community-based science
In community-based research, the idea of “representativeness” shifts. It’s not just about how well your data matches a general population or landscape. It’s about what your sample actually represents, and why that matters.
Community science is often focused on specific places, species, or events. These aren’t abstract populations. They’re real landscapes, histories, and relationships. Community members may not need to sample randomly to get useful results. They already know where to look.
Take the example of a pond near a new construction site. The nearby community might already know that something unusual happened with the water last spring. That knowledge shapes both the research question and when to sample. Random sampling could easily miss the most important site, season, or signal. “Community science has a rich tradition of using theories and research designs that are consistent with its core value of contextualism” (Luke 2005: 185), where local knowledge provides that context.
A Real Example: Ice, Plastics, and Indigenous Knowledge
The Nunatsiavut Government in Labrador, Canada, regularly samples ice cores along well-used snowmobile routes. They’re not randomly sampling ice in general. They’re focused on the ice that matters most to Inuit who live and travel there, coupled with knowledge of where climate change is having the most impact based on observations. That’s purposive sampling.
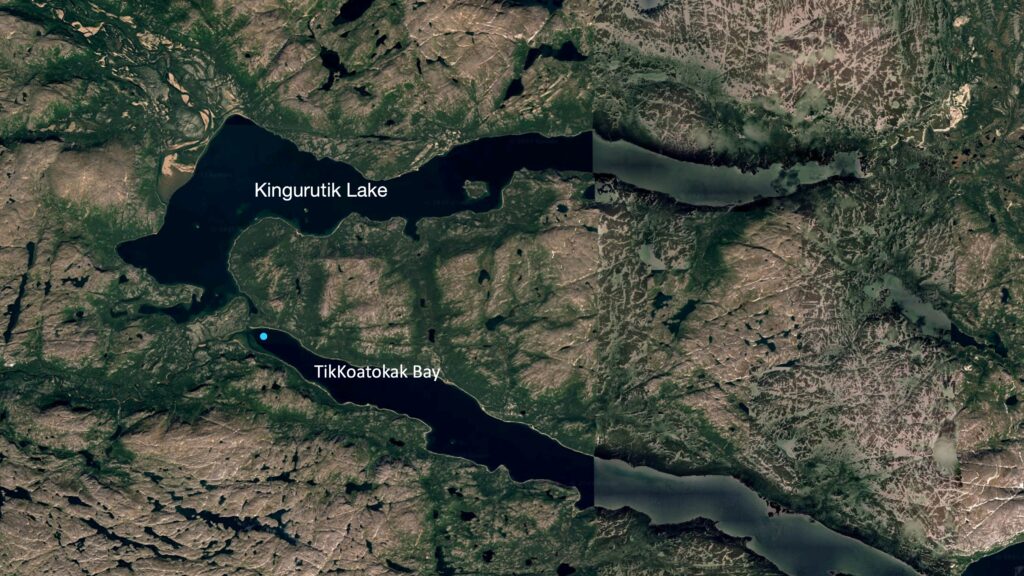
In 2025, our team at CLEAR analyzed some of those cores for plastic pollution in partnership with the Nunatsiavut Government. One core from the spring in Tikkoatokak Bay had far more plastics than the others. We were surprised—locals weren’t. They knew that meltwater from Kingurutik Lake flows into that spot in spring, stirring up debris. To them, more plastics there made perfect sense.
We didn’t need a random sample or hours in the lab to figure that out. The community already knew. In fact, while we were fussing with our data, Liz Pijogge, the Nunatsiavut Government’s Northern Contaminants Program Coordinator pointed out that the spring would be the time of most plastics in the environment. Of course, she was right, and her insight guided the data analysis (Liboiron and Pijogge, 2025).

If our goal had been to find the greatest variety of plastic types and sources, Nunatsiavummiut could have told us exactly where to sample: that same bay, in spring, near the stream. That’s a case of extreme case purposive sampling—choosing an unusual location likely to show a strong effect.
They also knew that spring is when iKaluit (Arctic char) leave Kingurutik Lake and are eating voraciously after a winter under the ice. Plastic ingestion by wild food is one of the community’s key research concerns. We sampled fish then, and yes, they ate a higher number of plastics in the spring, but nothing that appeared to harm the fish. The plastics were small and passed through. The takeaway: iKaluit are safe to eat.

What Makes Purposive Sampling Work
Relationships: Purposive sampling depends on contextual knowledge, and that means it depends on people.
If researchers aren’t from the community, they need relationships, time, skills, and humility to learn from those who are. As Rai and Thapa point out, if this knowledge isn’t available or accessible to researchers, purposive sampling won’t work (2015: 10). Building relationships takes time, but it also requires skills and knowledge of how to do research based in relationships (e.g. Layden et al. 2024, David-Chavez et al. 2024).
Scale: This method also works best at certain scales. It’s ideal for place-based or community-level research, where in-depth knowledge exists. It’s less suited to global studies, where that kind of insight may not exist at all.
Heterogeneity: Lastly, purposive sampling is especially helpful in heterogeneous environments where conditions vary a lot from place to place or group to group. Purposive sampling assumes that your samples aren’t interchangeable.
Purposive sampling and power
Even when scientists claim to use random sampling, they’re often relying on purposive decisions without realizing it. But the contextual knowledge is unrecognized, ignored, or lost, which results in not understanding that the knowledge is biased.
For example, Jess Melvin and colleagues reviewed shoreline plastic studies from over 3,000 sites worldwide (2021). They found that 90% were sandy beaches, and very few included snow or ice, even in northern regions. In fact, “three of these studies mentioned snow and ice as a justification for not conducting winter sampling, one study sampled during the winter season but avoided areas of snow cover” (2021: 5). Why? Because the standard sampling protocols assume sandy shores. That’s a hidden bias, not from randomness, but from the context those protocols were designed for.

When the decision to choose a site based on the protocol is not reported or discussed, it results in a global state of knowledge that likely underrepresents plastic concentrations on shorelines (Melvin et al. 2021).
A similar issue shows up in species selection to study plastic ingestion. Northern fulmars are often used by scientists who are not based in the North to monitor plastic ingestion in seabirds. Why? Because they forage exclusively at sea, have vast migratory ranges, forage in a way that makes them more likely to ingest plastics, and often wash up on beaches (Avery-Gomm et al. 2012: 1777). But this is a contextual choice, too, based on what scientists know about birds and what their research priorities are.
I have no problem with using contextual knowledge in science! The problem arises when Western-trained scientists assume that their contextual knowledge is more valid than that of communities. Even in collaborative projects, these tensions can surface. In a co-authored paper I was part of that included one community-based researcher, both Northern fulmars and community-identified species were discussed as plastic monitoring species, but the conclusion still leans toward Fulmars as the more scientific choice (Lusher et al. 2022). A better approach would have been a symmetrical discussion of the contexts, and thus the assumptions and values, behind both choices. Even better: we could have done an analysis of how each choice of sampling species impacted findings and the state of knowledge.
Acknowledging the context behind all sampling—random or purposive—can help rebalance power dynamics in research.
Reflexivity: Asking the Right Questions
Reflexivity, the ability to be aware of and question your own perspective and assumptions, is essential to strong research of any kind. Before designing a sampling strategy, ask:
- What exactly are we trying to represent?
- Who is making that decision—and why?
- What are the three main assumptions that shape the research? Where do they come from?
- What sampling method best fits your goals?
- What would a different sampling method show us?
- How can we be transparent about the knowledge guiding our choices?
These questions are best asked with a group of people with different perspectives and knowledge bases.
Answering these questions doesn’t just improve your sampling—it makes your research more accurate, relevant, and better equipped to inform real-world decisions.

References
Andersen, Chris. n.d. ‘The Statistical Field, Writ Indigenous’. Pp. 30–47 in Indigenous Statistics. Routledge.
Avery-Gomm, S., P. D. O’Hara, L. Kleine, V. Bowes, L. K. Wilson, and K. L. Barry. 2012. ‘Northern Fulmars as Biological Monitors of Trends of Plastic Pollution in the Eastern North Pacific’. Marine Pollution Bulletin 64(9):1776–81. doi:10.1016/j.marpolbul.2012.04.017.
Butler, Ashleigh E., Beverley Copnell, and Helen Hall. 2018. ‘The Development of Theoretical Sampling in Practice’. Collegian 25(5):561–66. doi:10.1016/j.colegn.2018.01.002.
Chasalow, Kyla, and Karen Levy. 2021. ‘Representativeness in Statistics, Politics, and Machine Learning’. Pp. 77–89 in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. Virtual Event Canada: ACM.
David-Chavez, Dominique, Michael Gavin, Norma Ortiz, Shelly Valdez, and Stephanie Carroll. 2024. ‘A Values-Centered Relational Science Model: Supporting Indigenous Rights and Reconciliation in Research’. Ecology and Society 29(2).
Layden, Tamara J., Sofía Fernández, Mynor Sandoval-Lemus, Kelsey J. Sonius, Dominique David-Chavez, and Sara P. Bombaci. 2024. ‘Shifting Power in Practice: Implementing Relational Research and Evaluation in Conservation Science’. Social Sciences 13(10):555.
Liboiron, Max, and Liz Pijogge. 2025. ‘Standard Western Science Measures for Environmental Monitoring Do Not Necessarily Serve Indigenous Research Priorities: Making Good Numbers in Nunatsiavut Plastic Monitoring’. Indigenous Computational Futures:1–12.
Lusher, Amy L., Jennifer F. Provencher, Julia E. Baak, Bonnie M. Hamilton, Katrin Vorkamp, Ingeborg G. Hallanger, Liz Pijogge, Max Liboiron, Madelaine Bourdages, Sjúrður Hammer, Maria Gavrilo, Jesse Vermaire, Jannie F. Linnebjerg, Mark L. Mallory, and Geir Wing Gabrielsen. 2022. ‘Monitoring Litter and Microplastics in Arctic Mammals and Bird’. Arctic Science. doi:10.1139/AS-2021-0058.
Melvin, Jessica, Madeline Bury, Justine Ammendolia, Charles Mather, and Max Liboiron. 2021. ‘Critical Gaps in Shoreline Plastics Pollution Research’. Frontiers in Marine Science 845.
Neyman, Jerzy. 1934. ‘On the Two Different Aspects of the Representative Method: The Method of Stratified Sampling and the Method of Purposive Selection’. Journal of the Royal Statistical Society 97(4):558–625. doi:10.2307/2342192.
Rai, Neetij, and Bikash Thapa. 2015. ‘A Study on Purposive Sampling Method in Research’. Kathmandu: Kathmandu School of Law 5(1):8–15.
This research has been funded by: The Killam Foundation, NSERC Discovery Horizons, SSHRC Insight Grant, Crown and Indigenous Affairs Canada, the Northern Contaminants Program, the Canada-Inuit Nunangat-United Kingdom Arctic Research Programme (CINUK), Memorial University, and the Nunatsiavut Government.